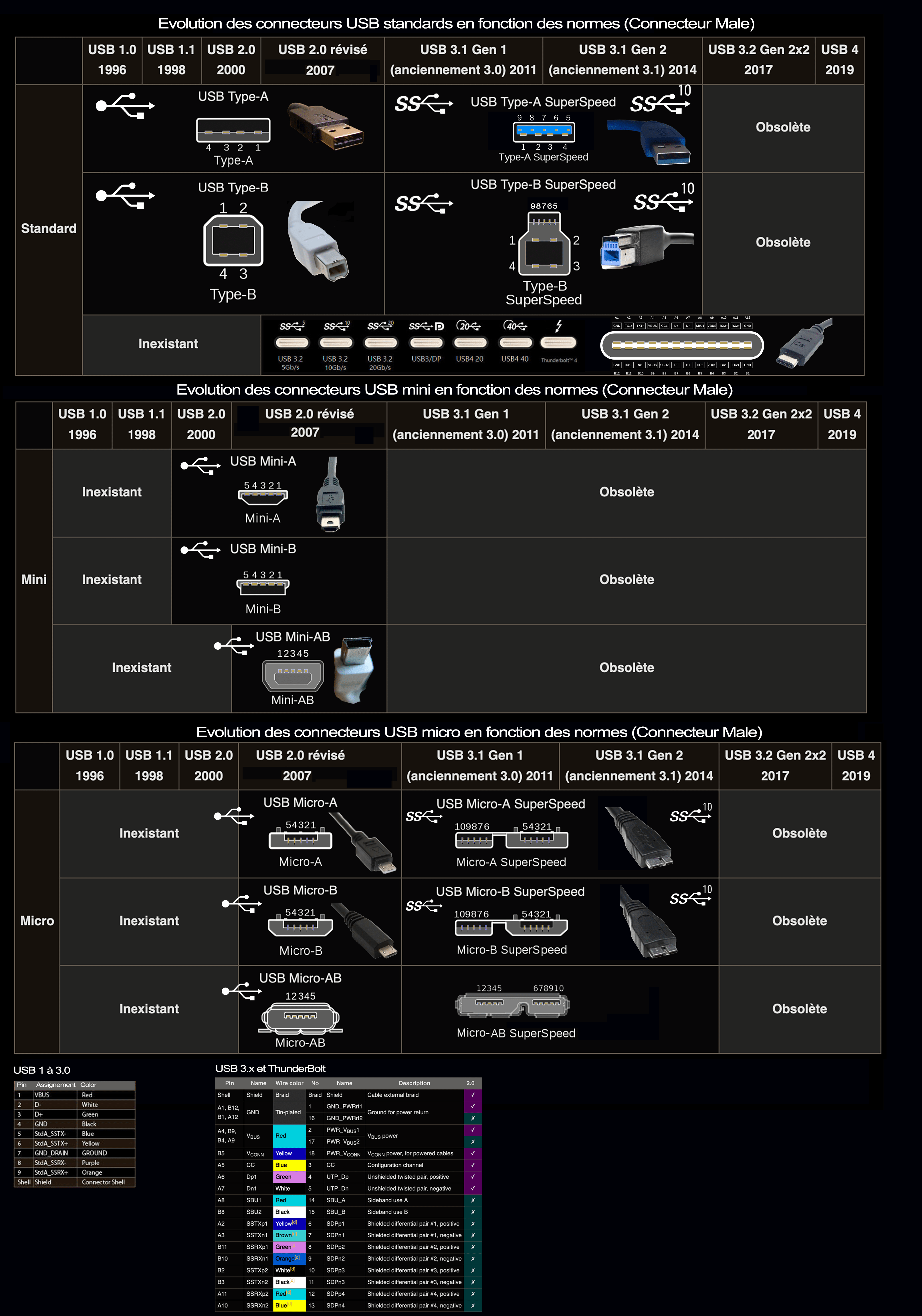
La norme et les câbles USB
USB est l’abréviation de “Universal Serial Bus” ou “Bus Universel en Série”. Il s’agit du type de connexion standard dont sont dotés beaucoup d’ordinateurs et divers périphériques.
Avant l’USB, il existait d’autres connecteurs, de l’ADB au FireWire et au SCSI, chacun avec ses propres caractéristiques.
Comme c’est le cas pour de nombreuses normes, l’USB n’a cessé de s’améliorer et d’offrir de nouvelles fonctionnalités.
Les différentes vitesses USB
Les vitesses USB sont d’abord assez simple à comprendre, rappelez-vous qu’un mégaoctet est huit fois plus grand qu’un mégabit (Mb). Dans les détails :
- L’USB 1.1 (Full-Speed) pouvait atteindre 12 mégabits par seconde (12Mbps), ce qui équivaut à 0,125 mégaoctet par seconde (Mbps).
- L’USB 2.0 (Hi-Speed) a une vitesse de 480 Mbps, soit 60 MBps.
- L’USB 3.0 (Super-Speed) a atteint de nouveaux sommets avec 5 gigabits par seconde (5Gbps), soit 625 MBps ou 5 000 Mbps.
Cette dernière norme s’est diversifiée, la preuve en est avec sa version 3.1 et ses deux variantes : USB 3.1 Gen 1, identique à USB 3.0 SuperSpeed, à 5 000 Mbps, et USB 3.1 Gen 2, SuperSpeed+, à 10 000 Mbps.
L’USB 3.2 est uniquement destiné à l’USB-C, et non à l’USB-A. Il ressemble à l’USB 3.1, en proposant une vitesse maximale de 10 Gbps.
Il est sujet à trois taux de transfert :
- USB 3.2 Gen 1 : USB SuperSpeed à 5 Gbps.
- USB 3.2 Gen 2 : USB SuperSpeed+ à 10 Gbps.
- USB 3.2 Gen 2×2 : USB SuperSpeed+ à 20 Gbps.
Un connecteur USB-C dispose de quatre paires de broches pour transmettre et recevoir les données.
Thunderbolt
Le Thunderbolt 3 (T3) variante produit par Apple, ressemble au USB-C, néanmoins il est beaucoup plus rapide (40,000 Mbps) et performant. Il fournit des données PCI Express pour les disques durs, les disques SSD et les cartes graphiques, ainsi que la fonctionnalité DisplayPort.
Il s’agit également d’un câble à pair et non d’un câble hôte, il a donc pour but de connecter plusieurs périphériques.
Le Thunderbolt 4 (T4) permet d’utiliser des câbles plus longs (2 m contre 1m pour le T3) et d’autres fonctions intéressantes, telles que la protection des données par accès direct à la mémoire (DMA) et le Hub. Tous les appareils compatibles prennent en charge au moins deux écrans externes 4K, ou un seul écran 8K.
La certification Thunderbolt 4 exige que la bande passante PCIe soit doublée à 32 Gbps.
USB 4 ou 4.0
Déjà présenté en 2019, l’USB 4.0 ou l’USB 4 vise avant tout à simplifier la diversité confuse des différentes spécifications et donc la jungle des appellations. Depuis l’arrivée de l’USB 3.0 et de ses générations suivantes sur les marchés à partir de 2019, on a facilement perdu la vue d’ensemble, car les connecteurs de cette génération étaient tous identiques. Les utilisateurs d’Apple le savent suffisamment. De nouveaux câbles et connecteurs ont dû être achetés. C’était la naissance du connecteur USB Type C. Il a également permis d’améliorer de manière significative la vitesse et la quantité d’électricité.
L’USB tytpe 4 à venir est basé sur le protocole Thunderbolt 3 qui prend en charge un débit allant jusqu’à 40 Gbps. Il a exactement la même apparence que l’USB-C, l’USB 3.2 et les Thunderbolt 3 et 4.
En plus de sa compatibilité avec le Thunderbolt 3, et sa rétrocompatibilité avec l’USB 3.2, ses spécifications minimales sont les suivantes : 20 Gbps, un écran 4K, une alimentation de 7,5 W, mais il peut aussi gérer jusqu’à 40 Gbps, deux écrans et une alimentation de 100 W.
Il peut fournir une alimentation d’au moins 15 W aux accessoires et prendre en charge deux écrans 4K ou un seul écran 8K.
Sinon, il existe aussi d’autres variantes :
- L’USB4 Gen 2×2 avec une bande passante de 20Gbps.
- L’USB4 Gen 3×2 qui atteint 40Gbps, le plus rapide à ce jour.
L’USB4 peut allouer dynamiquement et intelligemment la bande passante à la vidéo et aux données en fonction des besoins réels.
Nouvelle norme, nouveau logo:

USB 1.1
USB 1.1, développé en 1995, est le standard USB d’origine. Il gère deux vitesses de données : 12 Mbits/s pour les équipements comme les unités disques, qui nécessitent un débit élevé, et 1,5 Mbits/s pour les équipements comme les manettes de jeu, qui utilisent une bande passante bien moindre.
USB 2.0
En 2002, une nouvelle spécification, l’USB 2.0, ou USB 2.0 Hi-Speed, a été largement adoptée par les fabricants. Cette version est compatible à la fois en amont et en aval avec USB 1.1. Elle accélère le débit de la connexion entre le périphérique et le PC de 12 à 480 Mbits/s, soit un débit 40 fois plus rapide !
L’accroissement de bande passante améliore l’emploi de périphériques externes nécessitant des vitesses de transfert élevées, tels que les graveurs de CD/DVD, scanners, appareils photo numériques, équipements vidéo, etc. L’USB 2.0 prend en charge des applications exigeantes, comme la publication sue le Web, dans laquelle plusieurs appareils à haut débit fonctionnent en même temps. L’USB 2.0 est également pris en charge par Windows XP via une mise à jour.
USB 3.0
Le standard USB le plus récent, l’USB 3.0 ou « USB SuperSpeed » apporte de grandes améliorations par rapport à l’USB 2.0. L’USB 3.0 promet un débit allant jusqu’à 4,8 Gbits/s, presque dix fois celui de l’USB 2.0. L’USB 3.0 ajoute un bus physique fonctionnant en parallèle avec le bus 2.0 existant.
- Connecteurs
Il comprend la fiche USB plate de type A, mais à l’intérieur, il existe un autre jeu de connecteurs, et le bord de la fiche est bleu au lieu de blanc. La fiche type B a un aspect très différent avec un autre jeu de connecteurs. - Câble
Le câble USB 3.0 comprend neuf conducteurs, soit quatre de plus que le câble USB 2.0 qui en possède une paire pour les données et une paire pour l’alimentation électrique. L’USB 3.0 se sert de deux paires supplémentaires pour les données, pour un total de huit conducteurs, plus un de masse. Ces paires supplémentaires permettent à l’USB 3.0 de prendre en charge le transfert asynchrone bidirectionnel de données en full-duplex au lieu de la méthode d’interrogation de l’USB 2.0 en half-duplex. - Plus de puissance
L’USB 3.0 fournit 50% plus de puissance que l’USB 2.0 (150 mA contre 100 mA) aux dispositifs non configurés et jusqu’à 80% plus de puissance (900 mA contre 500 mA) aux appareils configurés. L’USB 3.0 gère aussi mieux l’énergie que l’USB 2.0 qui maintient l’alimentation quand le câble n’est pas utilisé.
Les caractéristiques USB définissent la vitesse et le fonctionnement du câble.
USB 2.0
C’est en 2002 que l’USB 2.0 (High-Speed) a été commercialisé. Cette version est rétrocompatible avec l’USB 1.1. Elle augmente la vitesse de connexion entre le périphérique et le PC de 12 Mo/s à 480 Mo/s, soit 40 fois supérieure à l’USB 1.1. Le nom du port comprend la mention « Enhanced », « Enhanced Host » ou « Universal Host ».
USB 3.1 Gen 1 (aussi appelé USB 3.0)
L’USB 3.0 (SuperSpeed) (2008) améliore les performances de l’USB 2.0. L’USB 3.0 peut atteindre une vitesse de 4,8 Go/s, soit 10 fois plus rapide que l’USB 2.0. L’USB 3.0 ajoute un bus physique actif en parallèle au bus 2.0 existant. L’USB 3.0 est rétrocompatible avec l’USB 2.0. Le nom du port indique USB 3.0.
USB 3.1 Gen 2
L’USB 3.1 (SuperSpeed+) offre une bande passante de 10 Go/s, un débit effectif de 3,4 Go/s et une alimentation de 900 mA en aval. A la différence de l’USB 2.0, la version 3.1 Gen 2 fonctionne en full duplex. La norme USB 3.1 Gen 2 est rétrocompatible avec les modèles 3.1 Gen 1 (ou 3.0) et USB 2.0.
Quels sont les différents types de raccords USB ?
USB Type A
- On les trouve généralement côté hôte (PC, clavier, serveur, hub, câbles et petits périphériques)
- Forme rectangulaire avec quatre broches en ligne
- Raccord bleu facilement reconnaissable
USB Type B
- Généralement utilisé sur les périphériques et autres appareils disposant d’un câble d’alimentation, comme les imprimantes
- Format carré avec coins arrondis d’un côté
- Quatre broches, une dans chaque coin.
USB Mini Type B
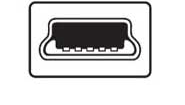
- Forme rectangulaire avec cinq broches
- Généralement utilisé sur les appareils photo et autres petits dispositifs
Micro Type-B avec câble 2.0
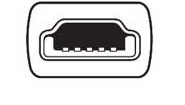
- Appareils mobiles et portables
- Forme rectangulaire avec cinq broches de 500 mA
USB Micro Type-B avec câble 3.1 Gen 1 (ou 3.0)
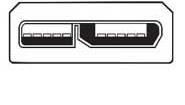
- Appareils mobiles et portables
- Alimentation de 900 mA
USB Type C
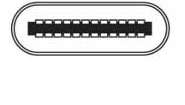
- Compatible avec l’hôte et le périphérique. Les raccords sont les mêmes des deux côtés. Forme oblongue.
- Compatible avec les modes alternés pour le transfert de données et autres à travers le raccord et le câble
- Peut être fixé à un n’importe quel port. Le fonctionnement est défini par le matériel.
- Prise réversible (haut ou bas)
- Port réversible avec 24 broches. Fixation rapide et facile.
- Débit jusqu’à 40 Go/s sur quatre voies de 10 Go/s chacune
- Peut fournir ou consommer du courant et produire jusqu’à 100 W
- Résiste à 10 000 cycles.
- Rétrocompatible